Z-Scores, Sampling Distributions and Confidence Intervals
This lab has three goals:
Learn how to calculate z-scores in R using different methods
Investigate the ways in which the statistics from a random sample of data can serve as point estimates for population parameters. We’re interested in formulating a sampling distribution of our estimate in order to learn about the properties of the estimate, such as its distribution.
Investigate the uncertainty that surrounds a point estimate using a confidence interval.
Calculating Z-Scores
The Data
For this z-score portion of this lab, we will use the mtcars dataset again. Begin by loading the dataset to the workspace. Do a quick clean/screen. Recode the categorical variables as factors.
data(mtcars)
There are several ways to calculate z-scores in R. First, we will calculate them manually using the formula for a z-score: $$ z =\frac{x - \bar{x}}{s} $$
Calculate the mean, standard deviation, and n for each variable and save them each to an object. We will do this for the mpg variable in mtcars.
mean.mpg <-mean(mtcars$mpg) #mean of mpg
sd.mpg <- sd(mtcars$mpg) #SD of mpg
N.mpg <-length(mtcars$mpg) #n for mpg
Now we can write a formula that calculates the z-score for each mpg score in the dataset.
mpg.z1 <- (mtcars$mpg - mean.mpg)/sd.mpg
The object mpg.z1 should now appear under “Values” in the Environment. We should make sure that our calculation worked liked we wanted it to. Z-scores should have a mean of 0 and an SD of 1.
options(scipen=999) #turns off scientific notation
mean(mpg.z1)
## [1] 0.00000000000000007112366
sd(mpg.z1)
## [1] 1
Rather than calculate each component of the equation separately, we could just write one equation that builds in those calculations.
mpg.z2 <- ((mtcars$mpg - mean(mtcars$mpg))/sd(mtcars$mpg))
mean(mpg.z2)
## [1] 0.00000000000000007112366
sd(mpg.z2)
## [1] 1
The final method we could calculate z-scores is to use the scale function. We will also use the %>% here so will need to make sure the dplyr package is loaded.
mtcars<- mtcars %>%
mutate(mpg.z3 = scale(mpg))
With the code above, the z-scored variable mpg.z3 is saved as a variable within the mtcars dataset (and not as a standalone object, like mpg.z1 and mpg.z2).
- Calculate z-scores for the
hpanddispvariables.
Using z-scores to detect outliers
Z-scores can be useful in detecting extreme scores on a variable. Remember that z-scores correspond to area under the curve. Scores that are in the tails of the normal distribution are extreme. The general rule is that scores that are more than 3 SD away from the mean (in either direction) are considered outliers. The scale function can be used to create z-scores. Once you create the z-scores, you can click on the object in the Environment to view, and the sort by clicking the little triangle near the varibale name. Then you can scroll through to see if there are any out-of-range z-scores. Alternavtively, you can ask R to tell you how many cases are good or bad.
Create an object called zmpg where the z-scores for mpg are stored. The second line of code tells us how many cases we have with z-scores less than the absolute value of 3.
zmpg <- scale(mtcars$mpg)
summary(abs(zmpg) < 3)
## V1
## Mode:logical
## TRUE:32
The output should say TRUE:32. This means that 32 cases have z-scores less than 3. Because there are 32 cases in the dataset, we do not have any outliers.
If there were cases we wanted to exclude, the subset function can be used to select the cases we want to keep. You can keep the subsetted data saved in a new data frame that you can then use in analyses going forward.
noout <- subset(mtcars, abs(zmpg) < 3)
Sampling Distributions
The Data
We consider real estate data from the city of Ames, Iowa. The details of every real estate transaction in Ames is recorded by the City Assessor’s office. Our particular focus for this lab will be all residential home sales in Ames between 2006 and 2010. This collection represents our population of interest. In this lab we would like to learn about these home sales by taking smaller samples from the full population. Let’s load the data.
download.file("http://www.openintro.org/stat/data/ames.RData", destfile = "ames.RData")
load("ames.RData")
We see that there are quite a few variables in the data set, enough to do a very in-depth analysis. For this lab, we’ll restrict our attention to just two of the variables: the above ground living area of the house in square feet (Gr.Liv.Area) and the sale price (SalePrice). To save some effort throughout the lab, create two variables with short names that represent these two variables.
area <- ames$Gr.Liv.Area
price <- ames$SalePrice
Let’s look at the distribution of area in our population of home sales by calculating a few summary statistics and making a histogram.
summary(area)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 334 1126 1442 1500 1743 5642
hist(area)
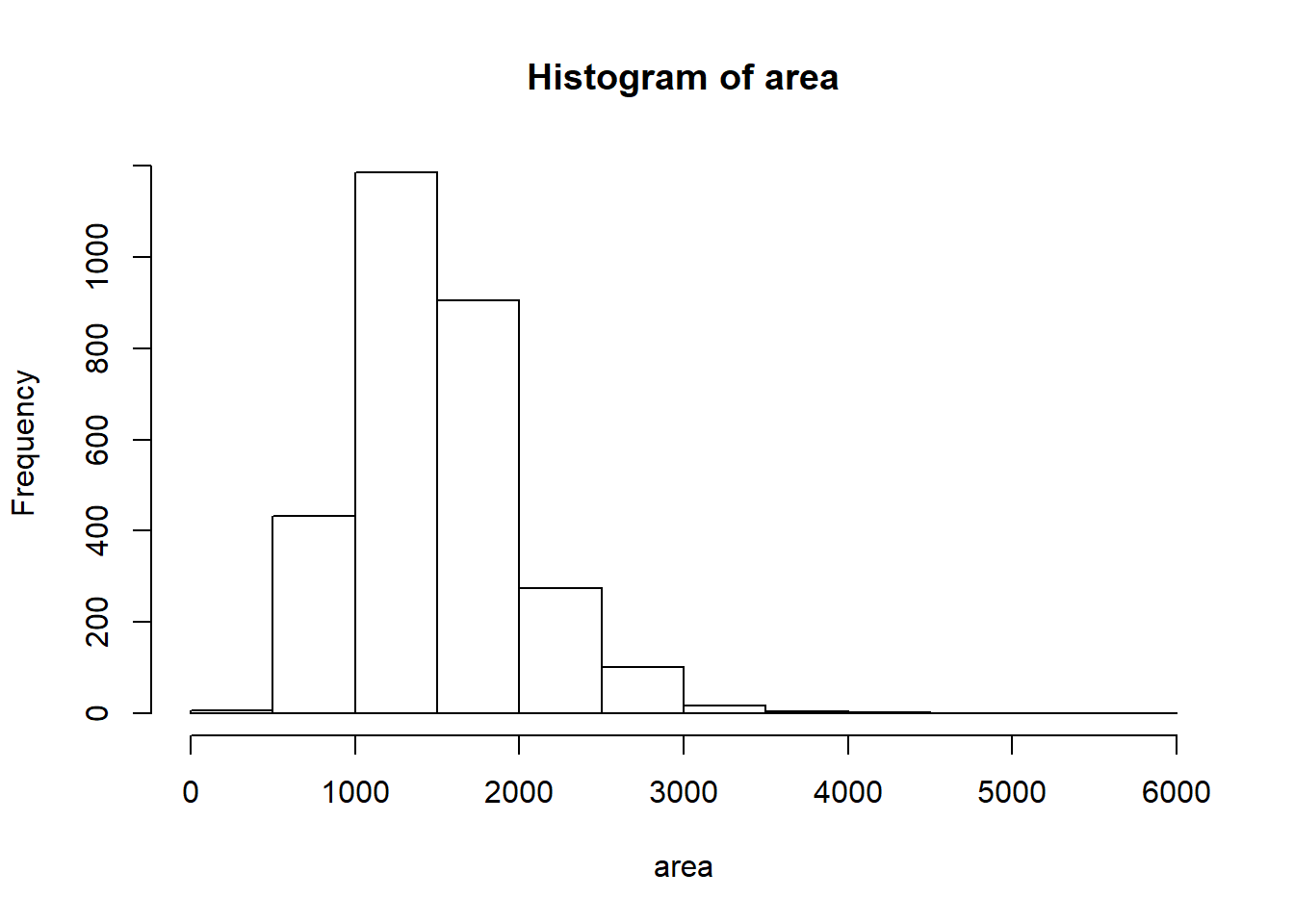
- Describe this population distribution.
The unknown sampling distribution
In this lab we have access to the entire population, but this is rarely the case in real life. Gathering information on an entire population is often extremely costly or impossible. Because of this, we often take a sample of the population and use that to understand the properties of the population.
If we were interested in estimating the mean living area in Ames based on a sample, we can use the following command to survey the population.
samp1 <- sample(area, 50)
This command collects a simple random sample of size 50 from the vector area, which is assigned to samp1. This is like going into the City Assessor’s database and pulling up the files on 50 random home sales. Working with these 50 files would be considerably simpler than working with all 2930 home sales.
- Describe the distribution of this sample. How does it compare to the distribution of the population?
If we’re interested in estimating the average living area in homes in Ames using the sample, our best single guess is the sample mean.
mean(samp1)
## [1] 1336.88
Depending on which 50 homes you selected, your estimate could be a bit above or a bit below the true population mean of 1499.69 square feet. In general, though, the sample mean turns out to be a pretty good estimate of the average living area, and we were able to get it by sampling less than 3\% of the population.
- Take a second sample, also of size 50, and call it
samp2. How does the mean ofsamp2compare with the mean ofsamp1? Suppose we took two more samples, one of size 100 and one of size 1000. Which would you think would provide a more accurate estimate of the population mean?
samp2 <- sample(area, 50)
mean(samp2)
## [1] 1527.78
Not surprisingly, every time we take another random sample, we get a different sample mean. It’s useful to get a sense of just how much variability we should expect when estimating the population mean this way. The distribution of sample means, called the sampling distribution, can help us understand this variability. In this lab, because we have access to the population, we can build up the sampling distribution for the sample mean by repeating the above steps many times. Here we will generate 5000 samples and compute the sample mean of each.
sample_means50 <- rep(NA, 5000)
for(i in 1:5000){
samp <- sample(area, 50)
sample_means50[i] <- mean(samp)
}
hist(sample_means50)
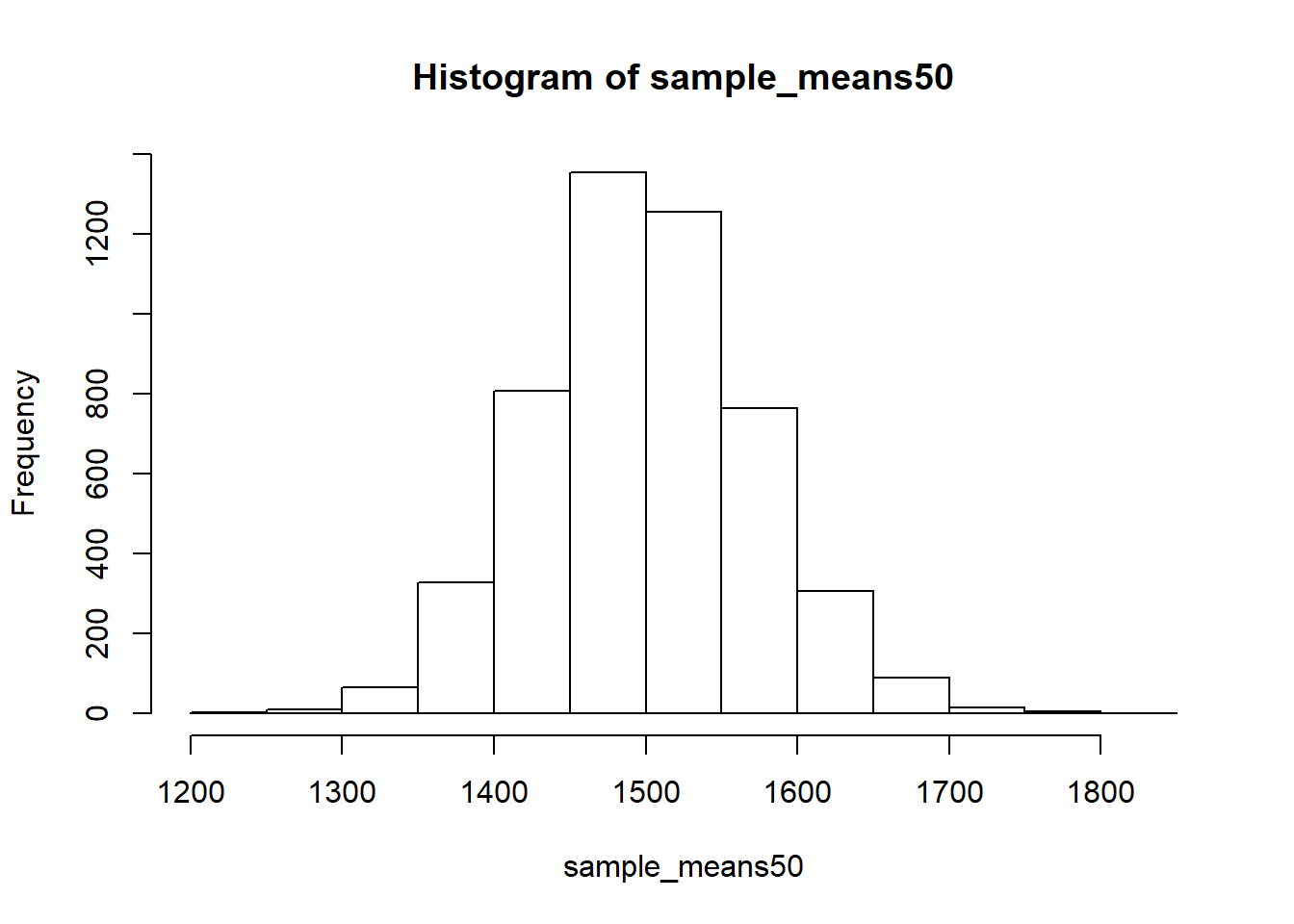
If you would like to adjust the bin width of your histogram to show a little more detail, you can do so by changing the breaks argument.
hist(sample_means50, breaks = 25)
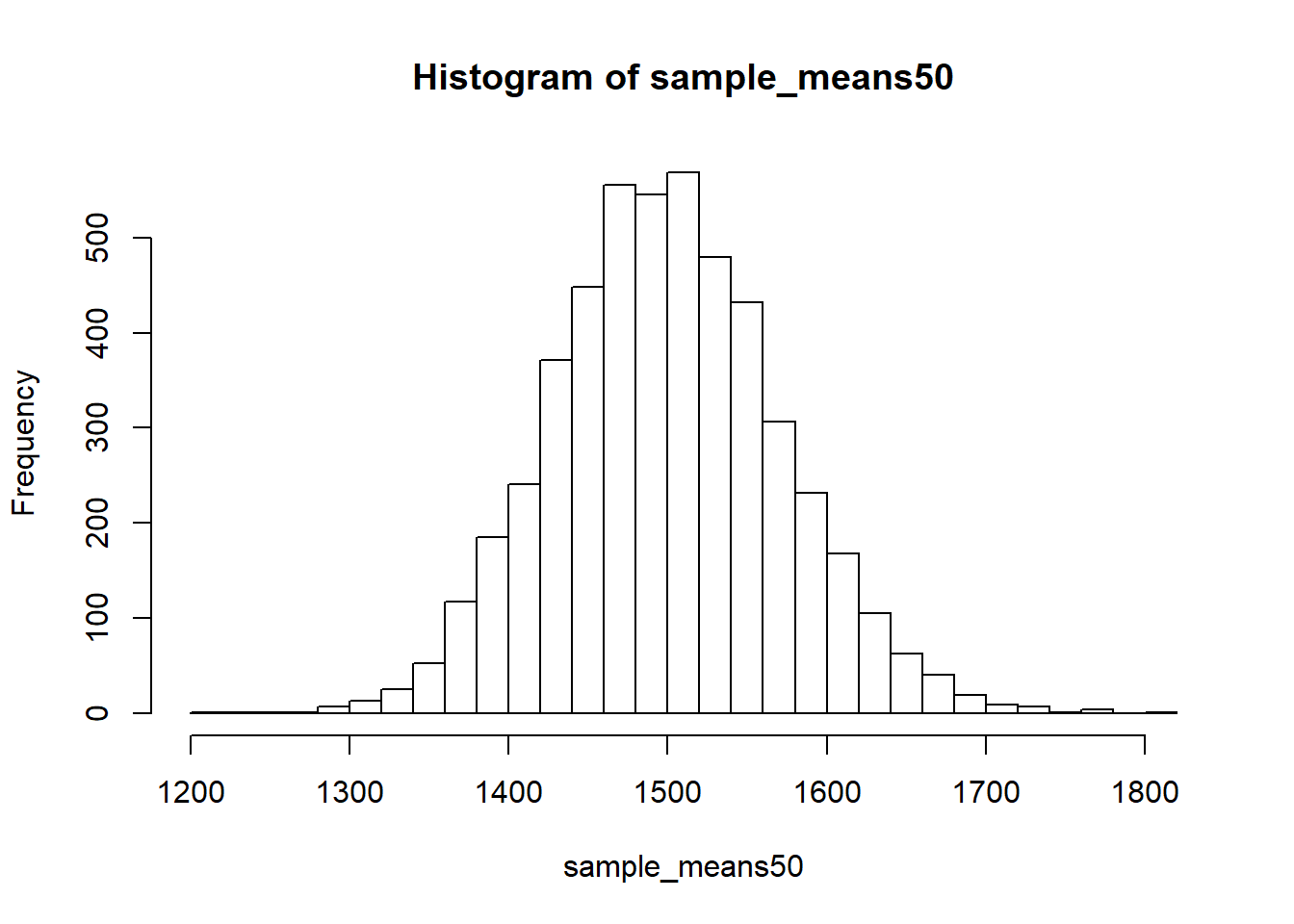
Here we just used R to take 5000 samples of size 50 from the population, calculated the mean of each sample, and stored each result in a vector called sample_means50. We’ll break down the code we just used to accomplish this task shortly.
- How many elements are there in
sample_means50? Describe the sampling distribution, and be sure to specifically note its center. Would you expect the distribution to change if we instead collected 50,000 sample means?
Interlude: The for loop
Let’s take a break from the statistics for a moment to let that last big block of code sink in. You have just run your first for loop, a cornerstone of computer programming. The idea behind the for loop is iteration: it allows you to execute code as many times as you want without having to type out every iteration. In the case above, we wanted to iterate the two lines of code inside the curly braces that take a random sample of size 50 from area then save the mean of that sample into the sample_means50 vector. Without the for loop, this would be painful:
sample_means50 <- rep(NA, 5000)
samp <- sample(area, 50)
sample_means50[1] <- mean(samp)
samp <- sample(area, 50)
sample_means50[2] <- mean(samp)
samp <- sample(area, 50)
sample_means50[3] <- mean(samp)
samp <- sample(area, 50)
sample_means50[4] <- mean(samp)
and so on…
With the for loop, these thousands of lines of code are compressed into a handful of lines. We’ve added one extra line to the code below, which prints the variable i during each iteration of the for loop. Run this code.
sample_means50 <- rep(NA, 5000)
for(i in 1:5000){
samp <- sample(area, 50)
sample_means50[i] <- mean(samp)
print(i)
}
Let’s consider this code line by line to figure out what it does. In the first line we initialized a vector. In this case, we created a vector of 5000 zeros called sample_means50. This vector will will store values generated within the for loop.
The second line calls the for loop itself. The syntax can be loosely read as, “for every element i from 1 to 5000, run the following lines of code”. You can think of i as the counter that keeps track of which loop you’re on. Therefore, more precisely, the loop will run once when i = 1, then once when i = 2, and so on up to i = 5000.
The body of the for loop is the part inside the curly braces, and this set of code is run for each value of i. Here, on every loop, we take a random sample of size 50 from area, take its mean, and store it as the \(i\)th element of sample_means50.
In order to display that this is really happening, we asked R to print i at each iteration. This line of code is optional and is only used for displaying what’s going on while the for loop is running.
The for loop allows us to not just run the code 5000 times, but to neatly package the results, element by element, into the empty vector that we initialized at the outset.
- To make sure you understand what you’ve done in this loop, try running a
smaller version. Initialize a vector of 100 zeros called
sample_means_small. Run a loop that takes a sample of size 50 fromareaand stores the sample mean insample_means_small, but only iterate from 1 to 100. Print the output to your screen (typesample_means_smallinto the console and press enter). How many elements are there in this object calledsample_means_small? What does each element represent?
Sample size and the sampling distribution
Mechanics aside, let’s return to the reason we used a for loop: to compute a sampling distribution, specifically, this one.
hist(sample_means50)
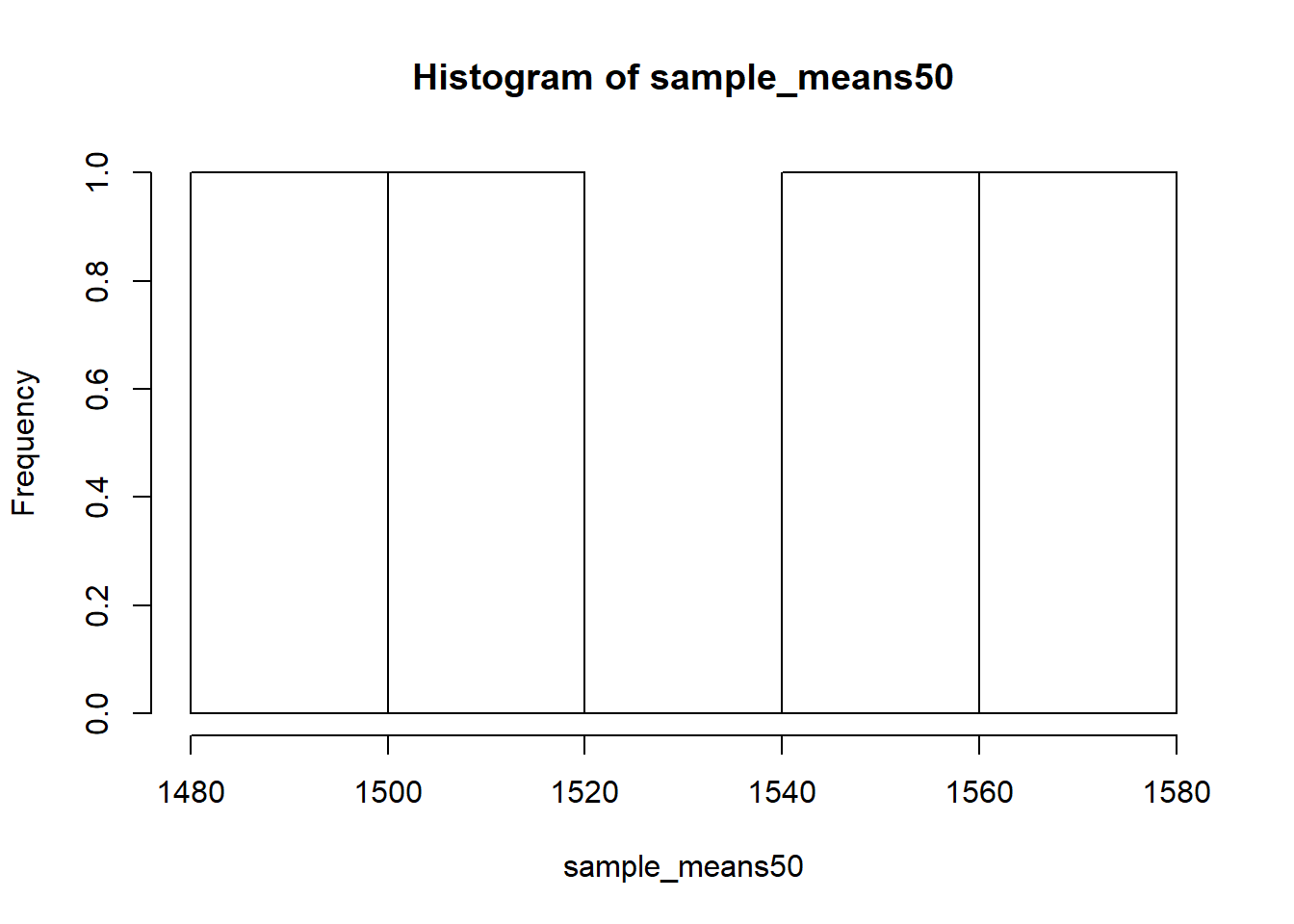
The sampling distribution that we computed tells us much about estimating the average living area in homes in Ames. Because the sample mean is an unbiased estimator, the sampling distribution is centered at the true average living area of the the population, and the spread of the distribution indicates how much variability is induced by sampling only 50 home sales.
To get a sense of the effect that sample size has on our distribution, let’s build up two more sampling distributions: one based on a sample size of 10 and another based on a sample size of 100.
sample_means10 <- rep(NA, 5000)
sample_means100 <- rep(NA, 5000)
for(i in 1:5000){
samp <- sample(area, 10)
sample_means10[i] <- mean(samp)
samp <- sample(area, 100)
sample_means100[i] <- mean(samp)
}
Here we’re able to use a single for loop to build two distributions by adding additional lines inside the curly braces. Don’t worry about the fact that samp is used for the name of two different objects. In the second command of the for loop, the mean of samp is saved to the relevant place in the vector sample_means10. With the mean saved, we’re now free to overwrite the object samp with a new sample, this time of size 100. In general, anytime you create an object using a name that is already in use, the old object will get replaced with the new one.
To see the effect that different sample sizes have on the sampling distribution, plot the three distributions on top of one another.
par(mfrow = c(3, 1))
xlimits <- range(sample_means10)
hist(sample_means10, breaks = 20, xlim = xlimits)
hist(sample_means50, breaks = 20, xlim = xlimits)
hist(sample_means100, breaks = 20, xlim = xlimits)
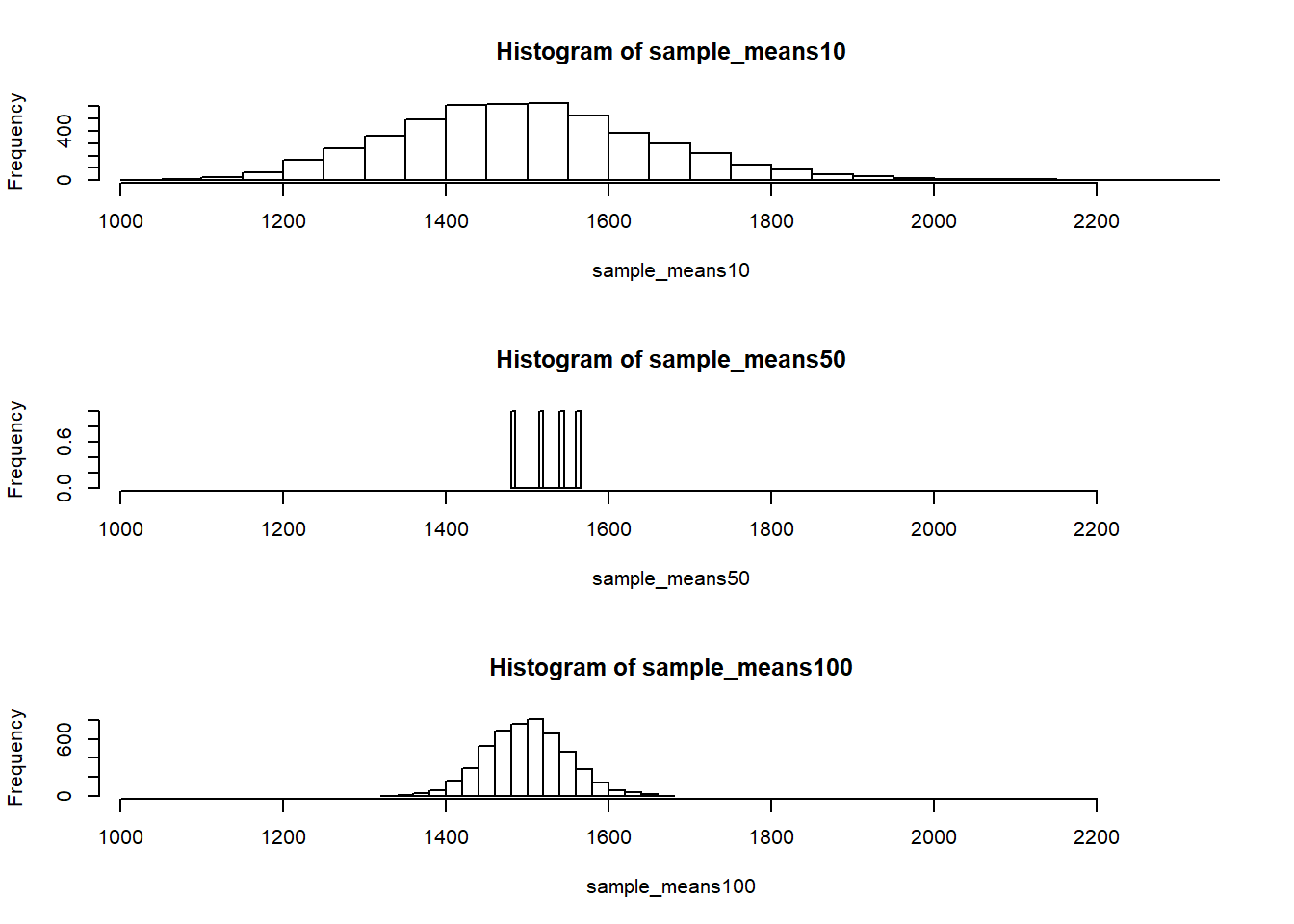
The first command specifies that you’d like to divide the plotting area into 3 rows and 1 column of plots (to return to the default setting of plotting one at a time, use par(mfrow = c(1, 1))). The breaks argument specifies the number of bins used in constructing the histogram. The xlim argument specifies the range of the x-axis of the histogram, and by setting it equal to xlimits for each histogram, we ensure that all three histograms will be plotted with the same limits on the x-axis.
- When the sample size is larger, what happens to the center? What about the spread?
On your own
So far, we have only focused on estimating the mean living area in homes in Ames. Now you’ll try to estimate the mean home price.
Take a random sample of size 50 from
price. Using this sample, what is your best point estimate of the population mean?Since you have access to the population, simulate the sampling distribution for
\(\bar{x}_{price}\)by taking 5000 samples from the population of size 50 and computing 5000 sample means. Store these means in a vector calledsample_means50. Plot the data, then describe the shape of this sampling distribution. Based on this sampling distribution, what would you guess the mean home price of the population to be? Finally, calculate and report the population mean.Change your sample size from 50 to 150, then compute the sampling distribution using the same method as above, and store these means in a new vector called
sample_means150. Describe the shape of this sampling distribution, and compare it to the sampling distribution for a sample size of 50. Based on this sampling distribution, what would you guess to be the mean sale price of homes in Ames?Of the sampling distributions from 2 and 3, which has a smaller spread? If we’re concerned with making estimates that are more often close to the true value, would we prefer a distribution with a large or small spread?
Confidence Intervals
Each mean in the sampling distributions is a point estimate of the population mean. Some means are above the population mean, while others are below it. Each mean has estimation error: (M – μ), or the distance between our point estimate based on the sample, and the population parameter we are estimating. The Margin of Error (MoE) is the largest likely estimation error. Most often, we use 95%, such that 95% of the means will fall in the MoE.
We can calculate a 95% confidence interval for a sample mean by adding and subtracting 1.96 standard errors to the point estimate.
se <- sd(samp) / sqrt(60)
sample_mean <- mean(samp)
lower <- sample_mean - 1.96 * se
upper <- sample_mean + 1.96 * se
c(lower, upper)
## [1] 1350.406 1599.674
This is an important inference that we’ve just made: even though we don’t know what the full population looks like, we’re 95% confident that the true average size of houses in Ames lies between the values lower and upper. There are a few conditions that must be met for this interval to be valid.
For the confidence interval to be valid, the sample mean must be normally distributed and have standard error
s/sqrt(n). What conditions must be met for this to be true?What does “95% confidence” mean?
In this case we have the luxury of knowing the true population mean since we have data on the entire population. This value can be calculated using the following command:
mean(area)
## [1] 1499.69
Does your confidence interval capture the true average size of houses in Ames? If you are working on this lab in a classroom, does your neighbor’s interval capture this value?
Each student in your class should have gotten a slightly different confidence interval. What proportion of those intervals would you expect to capture the true population mean? Why? If you are working in this lab in a classroom, collect data on the intervals created by other students in the class and calculate the proportion of intervals that capture the true population mean.
Using R, we’re going to recreate many samples to learn more about how sample means and confidence intervals vary from one sample to another. Loops come in handy here.
Here is the rough outline:
- Obtain a random sample.
- Calculate and store the sample’s mean and standard deviation.
- Repeat steps (1) and (2) 50 times.
- Use these stored statistics to calculate many confidence intervals.
But before we do all of this, we need to first create empty vectors where we can save the means and standard deviations that will be calculated from each sample. And while we’re at it, let’s also store the desired sample size as n.
samp_mean <- rep(NA, 50)
samp_sd <- rep(NA, 50)
n <- 60
Now we’re ready for the loop where we calculate the means and standard deviations of 50 random samples.
for(i in 1:50){
samp <- sample(area, 60) # obtain a sample of size n = 60 from the population
samp_mean[i] <- mean(samp) # save sample mean in ith element of samp_mean
samp_sd[i] <- sd(samp) # save sample sd in ith element of samp_sd
}
Lastly, we construct the confidence intervals.
lower_vector <- samp_mean - 1.96 * samp_sd / sqrt(n)
upper_vector <- samp_mean + 1.96 * samp_sd / sqrt(n)
Lower bounds of these 50 confidence intervals are stored in lower_vector,
and the upper bounds are in upper_vector. Let’s view the first interval.
c(lower_vector[1], upper_vector[1])
## [1] 1425.26 1664.74
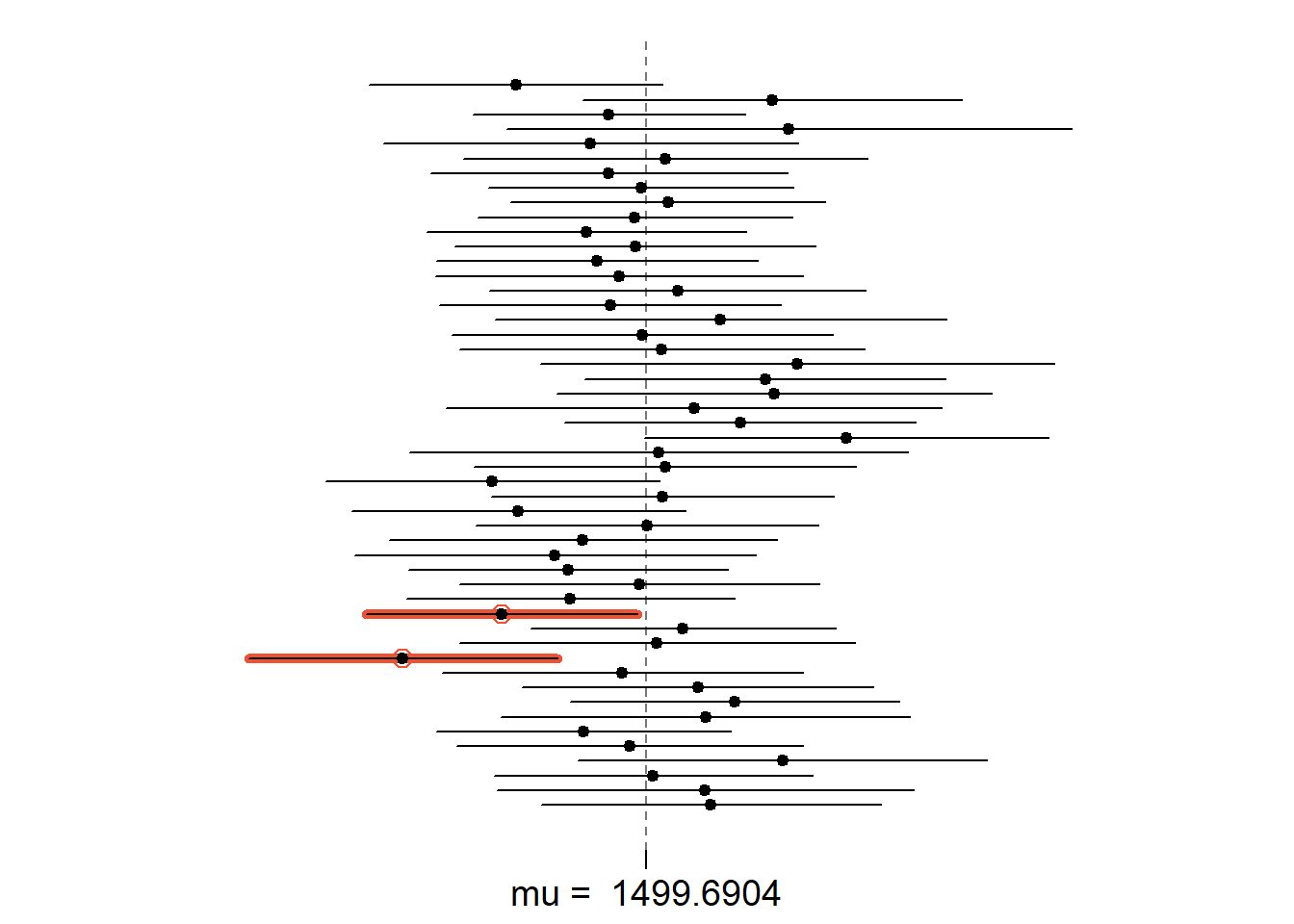
Using the following function (which was downloaded with the data set), plot all intervals. What proportion of your confidence intervals include the true population mean? Is this proportion exactly equal to the confidence level? If not, explain why.
plot_ci(lower_vector, upper_vector, mean(area))
Some helpful functions that you might need when calculating critical z or t-statistics.
#gives the area, or probability, below a z-value
pnorm()
#gives the critical z-value corresponding to a lower-tailed area
qnorm()
#to find critical value for a two-tailed 95% CI:
qnorm(1-.05/2)
#gives the critical t-values corresponding to a lower-tailed area with 25 df:
qt(.05, 25)
#to find the critical t-value for a 95% CI with 25 degrees of freedom:
qt(1-.05/2, 25)